hardrails — budget-enforcement-demo
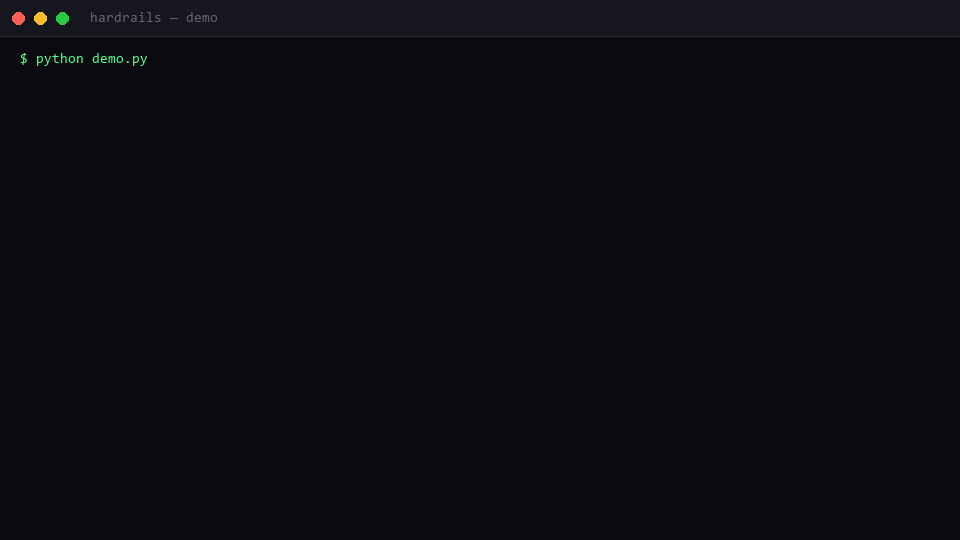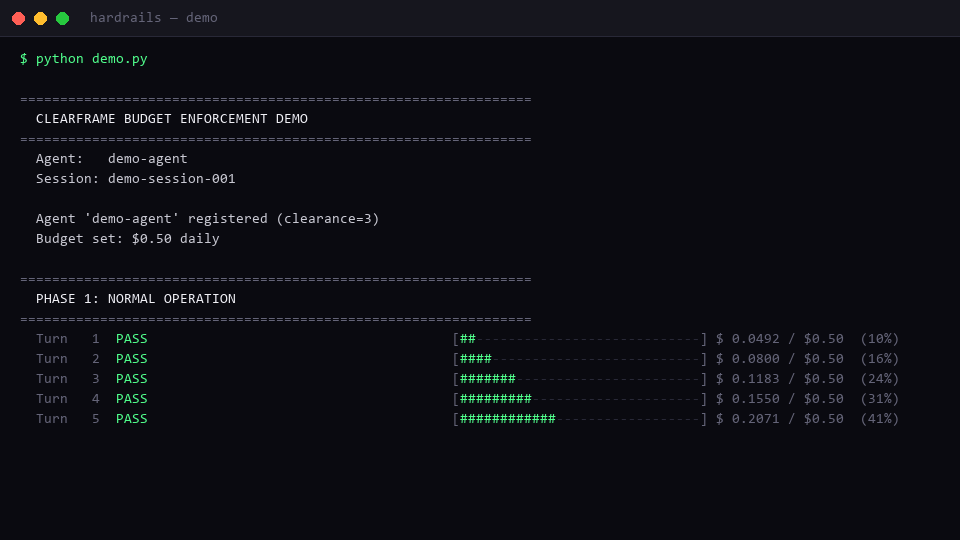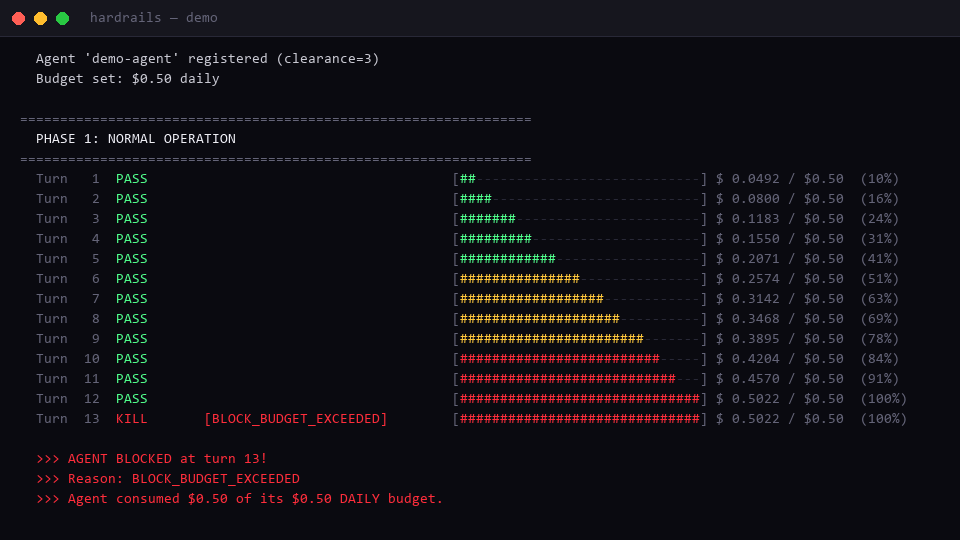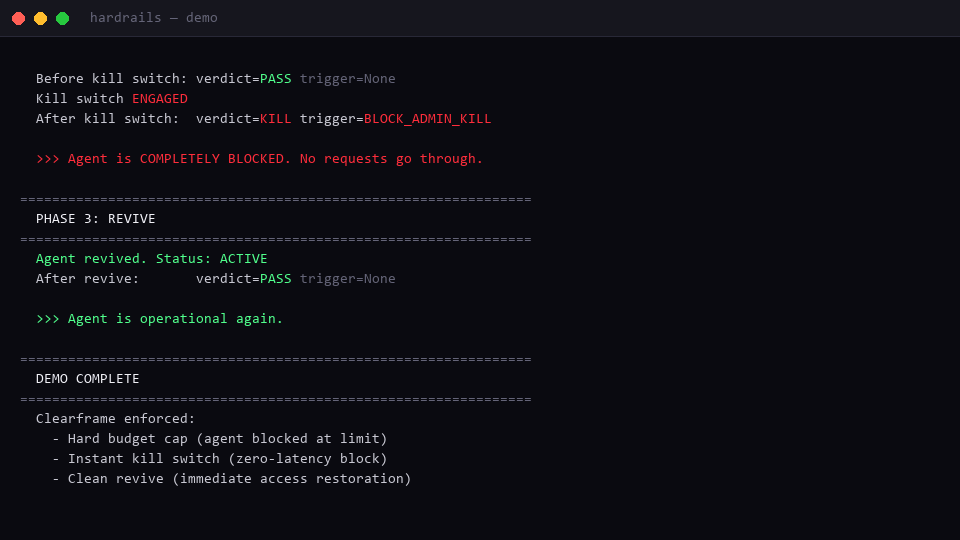
Agent burns through $0.50 budget in 12 turns → hard block at turn 13 → kill switch → revive
Guardrails are suggestions. Hard rails are physics. Enforce deterministic spend caps and real‑time kill switches on your LangChain/CrewAI fleet with zero code changes.
Agent burns through $0.50 budget in 12 turns → hard block at turn 13 → kill switch → revive
The Problem
Every AI platform is deploying autonomous agents. Those agents make API calls, spend budget, touch production systems. There is no standard layer to ask: who authorized this? how much has been spent? what exactly happened?
The Wedge
HardRails is a local HTTP proxy that sits between your agent framework and the upstream LLM API. It intercepts, meters, and blocks before the API call leaves your server.
# Before — agent talks directly to OpenAI
export OPENAI_BASE_URL=https://api.openai.com/v1
# After — HardRails sits in the middle
export OPENAI_BASE_URL=http://localhost:4100/v1
Your Agent
LangChain / CrewAI / raw
HARDRAILS
intercept · meter · block
HARDRAILS
intercept · meter · block
OpenAI API
or any compatible endpoint
Why HardRails
HardrailsAI wraps any agent framework. You define the rules — we enforce them deterministically, before the action executes.
Cryptographic identity for every agent instance. Know exactly which agent took which action — across frameworks, clouds, and teams.
Hard ceilings on token spend, API calls, and compute per agent, per session, per policy class. No surprises on your cloud bill.
Declarative allow/deny policies evaluated before execution. Define what each agent is permitted to do — and enforce it at the boundary.
Tamper-proof, structured logs of every agent decision and action. Compliance-ready export. Human-reviewable reasoning traces.
Architecture
Under the Hood
Not a pitch deck — production Python running between your agents and the upstream API. Every intercept is deterministic. Every decision is logged.
@app.post("/v1/chat/completions")
async def chat_completions(request: Request):
body = await request.json()
# Extract governance context from headers
agent_id = request.headers.get("X-Agent-Id", DEFAULT_AGENT_ID)
session_id = request.headers.get("X-Session-Id")
prompt_text = _extract_prompt(body.get("messages", []))
# ── Governance intercept ─────────────────────────────
decision = _gateway.intercept(
agent_id = agent_id,
request_body = prompt_text,
session_id = session_id,
)
# Hard block — request never reaches the upstream API
if decision and decision.verdict in ("KILL", "SOFT_KILL"):
return _governance_error(decision)
# ── Forward to upstream ──────────────────────────────
# Agent only changed one env var. Everything else is invisible.
return await _forward(body, upstream_headers, stream)Zero code changes. Agents set OPENAI_BASE_URL=localhost:4100 — governance is invisible.
Pricing
Every plan includes the full governance proxy, budget enforcement, and kill switch. Choose the tier that fits your team.
Pro
Full governance stack with War Room dashboard and compliance exports.
Enterprise
Managed deployment, fleet-wide governance, and dedicated onboarding.